VITS学習メモ
このメモは以下の記事をある程度読んだ上で、自分が戸惑ったところなどを補完するためのものです。私以外が読んで理解の助けになるのかよく分かりません。そもそも間違っているかもしれません。書いてみると理解できていないところがよく分かっていいですね。というわけで分からんところは分からんって書きます。
参考記事:
【機械学習】VITSでアニメ声へ変換できるボイスチェンジャー&読み上げ器を作った話 - Qiita
参考コード:
https://github.dev/zassou65535/VITS
はじめに
各変数(潜在変数とか潜在表現とか)が何を意味しているのか分かりづらかったので、モジュールではなく変数に着目する形で図式化してみましたあ。
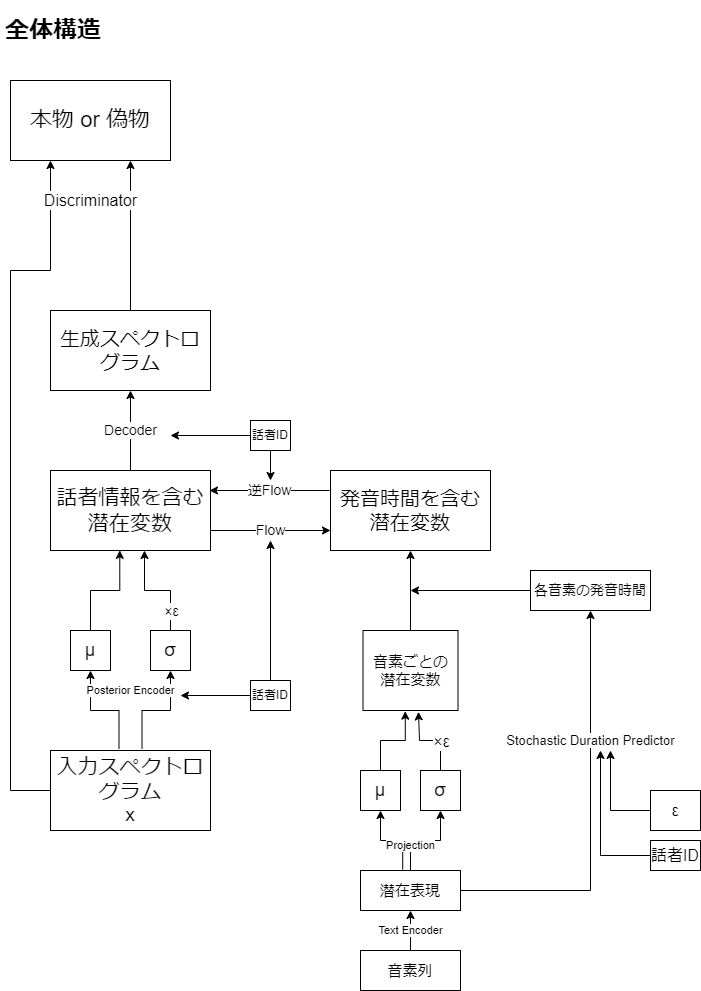
全体のイメージ図を描いただけで、実際にこのフロー通りに使われることはありません。
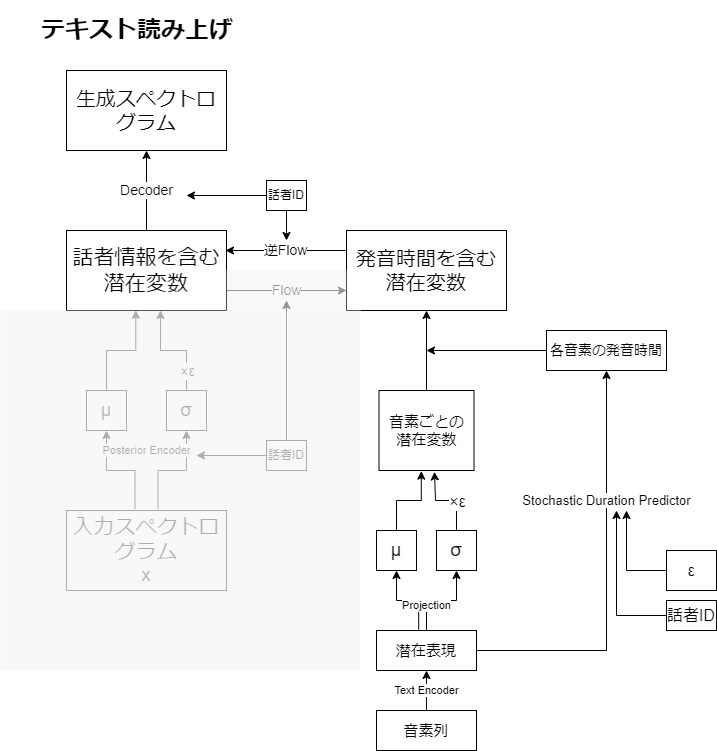
流れ自体は難しいことなさそうです。

Flowによって話者情報を入れ替えています。
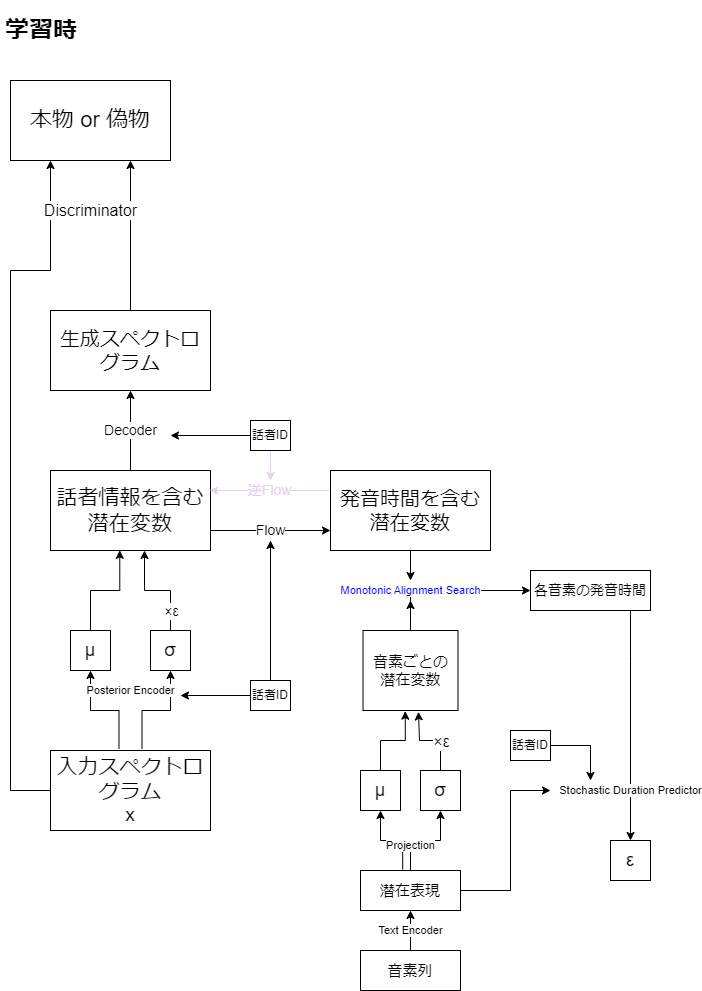
学習時は、Stochastic Duration Predictorの学習のため、各音素の発音時間を予測する必要があります。そのためにMonotonic Alignment Searchと呼ばれる手法を使っています。ここは学習パラメータがないので青文字にしています。
各モジュールの説明
私が最初に戸惑った原因として、VAEをEncoderとDecoderの組として、他のモジュールを切り離して考えてしまったことがあげられます。実際には事後分布を近似する、Posterior Encoder(事後エンコーダ)とテキスト条件付き事前分布
を近似するPrior Encoder(事前エンコーダ)、潜在変数が与えられたときの実際の音声分布
を近似するDecoder(デコーター)の三組からなるConditional VAEというアーキテクチャになっています。
- Posterior Encoder
スペクトログラムから潜在変数の平均と分散をだします。ネットワークにはWAVEGLOWというモデルで使われた構造がいくつか重なってできているようです(分かってない)。また話者IDも埋め込みベクトルに変換されて入力されます。Diffusion ModelのTime embeddingと同じで話者ごとにモデルを作らなくてもいいようにするということでしょうか。
- Text Encoder
テキストによる音素(謎のアルファベット列)を潜在表現に変換します。Transformerっぽいネットワークを使ってるらしい。
- Projection
Conv1d一層のみのネットワークで、潜在表現を入力にとり、平均と分散を出力することで多変量正規分布に置き換えます。
- Flow
逆変換可能で、確率変数の変数変換のために必要なヤコビアンが1になるようにうまーく設定されたネットワークです(あまり分かってない)。その性質により対数尤度が明示的に計算できます(あんまり分かってない)。役割は潜在変数から話者固有の情報を切り離すことです。逆変換可能なので、話者の入れ替えが可能になるということですね。またヤコビアンが1であることから、Projectionの出力分布からの変数変換を容易に行えます(分かってない)。Posterior Encoderと同じくWAVEGLOWの構造が使われているようです。
論文ではText Encoder、Projection、Flowを合わせてPrior Encoderと呼んでいます。
- Discriminator
音声が本物か生成されたものかを判定するネットワークです。DiscriminatorとVAEのDecoderが競いあうことで、精度をあげていきます。学習時は出力だけでなく、中間層の特徴量も真贋で一致するように損失が定義されます。
- Stochastic Duration Predictor
潜在表現から音声の発音時間を推定するためのネットワークです。学習時には潜在表現、話者ID、各音素のdurationを入力し、多変量正規分布にしたがったノイズを出力するよう学習します。推論時には潜在表現と話者ID、ノイズを入力としてdurationを出力します。2つのFlowがありますが、一方は一次元で離散的なdurationデータを高次元連続的なデータに落とし込むためのもので、推論時には使われません。(全然分かってない)
各状態について
各ネットワークの入力や出力の状態が一体どんな意味を持っているのか分かりづらかったのでまとめます。
- スペクトログラム
入力データそのもので、横軸に時刻、縦軸に周波数をとった振幅のデータです。短時間フーリエ変換によって求めるやつ(分かってない)。
- メルスペクトログラム
スペクトログラムにメル尺度をとって、人間にとって直感的な指標に変換します。pHとか星の等級とか、マグニチュードと同じようなやつですかね(分かってない)。再構成誤差を計算するときは、こちらを使うことでより人間にとっていい感じの音声を生成できるようにします。
- 話者情報を含む潜在変数
音声がもつ潜在的な情報で、それが正規分布となるように学習することによって色々と扱いやすくしています。
- 話者情報を含まない潜在変数
潜在変数から話者固有の情報を切り離し、一般的な発音の情報を抽出したものです。Flowにより話者情報の入れ替えが可能です。
- (テキストエンコーダによる)潜在表現
音素列をエンコードしたものです。そのままでは発音の長さの情報を持たないので、それを推定する必要があります。
- (Projectionによる)発音情報の平均と分散
潜在表現から多変量正規分布を出力します。学習時にはMonotonic Alignment Searchにより、この分布から潜在変数が出力される確率(尤度)が最大になるものをdurationとし、推論時はStochastic Duration Predictorからdurationを決定します。
推論フロー
テキストから音声への変換の場合、テキストを音素列に変え、音素列をテキストエンコーダに入力し、潜在表現を得ます。Stochastic Duration Predictorで各音素の発音時間を推定した後、逆Flowで話者情報を付与した潜在変数を獲得し、Decoderで音声を生成します。
音声変換の場合、音声をPosterior Encoderで潜在変数に変え、Flowと逆Flowにより話者情報を変換します。そしてDecoderで音声を生成します、
損失関数
Reconstruncion Loss:入力のメルスペクトログラムと出力のメルスペクトログラムの絶対値誤差です。ラプラス分布ってなんですか。
KL loss:通常のVAEと違って事前分布に条件(音素)が付いているので、項が増えています。その項がFlowやテキストエンコーダの損失関数に該当するという感じですかね。
Adversarial loss:GANの損失です。
Feature matching loss:識別器の中間層も本物の音声と同じような特徴を持つようにします。絶対値誤差の平均をとっているようです。
Duration loss:Stochastic Duration Predictorの損失ですが、よく分かりません。
ResNet vs Vision Transformer vs MLP-Mixer in おせろ
画像認識系ディープラーニング界隈を盛り上げる三英傑を、オセロで比較してみました。実装は一応貼っておくけど・・・Python3.8が必要です。
GitHub - laksjdjf/DeepReversi: 趣味で作った深層オセロAI
モデル構造
全てのモデルがオセロの盤面(白黒の2チャンネル×8×8の画像データ)を入力として、方策確率(64次元ベクトルでそれぞれのマスに打つ確率)と価値(1次元ベクトルで有利か不利かを表す)の2つを返す構造になっています。
ResNet
畳み込み2層+残差結合のResNetブロックをいくつも重ねて作ります。一応以前説明記事を書いています。
学習について
以前作った自己対局34万試合分のデータを使います。dlshogiの学習則をほぼそのまま利用しています。
3つのモデルすべて128チャンネル(埋め込み次元)、10ブロックでやりました。モデルサイズはResNetが20MB、ViTが8MB、MLP-Mixerが12MBくらいになってます。
でまあここで本当は学習ログなど貼るべきなのですが、色々試したりコードを変えながらやったのでありません。学習結果については、検証データの方策正解率や価値正解率は3つのモデルでだいたい同じになりました。ただし学習時間はかなり差があり、パラメータ数が一番小さいViTが一番時間かかりました。もうやりたくないレベルでかかりました。
結果、edaxというすごいオセロAIの5レベル(5手読み)を入れて総当たり戦で比較してみます。こちらは1000プレイアウトです。私のモデルは同じ結果にならないように10%の確率で次善手を打ちます。
| モデル | 勝敗 | Elo rating | 思考時間合計(秒) |
| ResNet | 160勝140敗 | 1533 | 2584 |
| ViT | 147勝153敗 | 1486 | 3052 |
| Mixer | 152勝148敗 | 1500 | 2744 |
| Edax 5 | 141勝159敗 | 1481 | 25※ |
※edaxは小数点3ケタしか返してくれないので丸め誤差あり。
どのモデルもあまり差がないですね。同じデータセットで同じくらいの正解率なので当たり前と言えば当たり前ですが。一応一番強くて一番思考時間が少ないのはResNetで、結局畳み込みが優秀なんじゃんという話になりました。実装も一番簡単ですしね。モデルのデータ量はResNetが一番大きいのですがそれでも20MBにしかならないのでどうでもいいです。ViTは実装も難しく学習時間も長いのでうんちです。MLP-Mixerは割とありって感じでした。
GPT2にアストルフォのdanbooruタグ付けをファインチューニングしてみた
text2imgによる画像生成について、textの方もAI任せにしてーと思っていたのでGPT2にプロンプトを自動生成させるのをやってみます。
以下をぱくっただけです。
github.com
説明
私が個人的にStable diffusion系モデルをファインチューニングするときに使うキャプションをそのまま学習用データとして利用します。キャラクタータグ以外はWD14-taggerによる推論結果を利用しています。順序は予測値でソートしています。
キャプション例:
astolfo, fate, memories at trifas, striped shirt, bow, hair bow, official alternate costume, looking at viewer, otoko no ko, solo, pleated skirt, midriff, hair ribbon, one eye closed, pantyhose, fang, skirt, braid, v, open mouth, collarbone, jacket, blush, black bow, shirt, necklace, black ribbon, sitting, crop top, jewelry, striped, black pantyhose, navel, smile, ribbon
特長として、memories at trifasといった、衣装を特徴づけるタグを残していることです(Waifu diffusionではおそらく消している)。求める自動生成として、例えば"astolfo,memories at trifas"と入力すれば、アポクリファ私服に合う"pantyhose"や"purple jacket"等を並べてくれることです。こうすれば特定の衣装のプロンプトを好きなように作成できそうですね。逆に"armor"や"sailor collar"といった関係ないタグを出してくるようでは、使い物にならなそうです。
10 epochやりました。
生成例
ここからはnsfwな単語がでてきます^^
よく考えたらアストルフォのタグ付けなんてほとんどの人なじみ無いから見ても分からないかもしれない。
- 特に指定なし
入力:astolfo,fate,solo,
出力:
astolfo,fate,solo, fate, sailor paladin, heart, bow, white shirt, cellphone, official alternate costume, looking at viewer, otoko no ko, solo, pink skirt, white thighhighs, pleated skirt, midriff, cowboy shot, hair ribbon, thighhighs, red skirt, sailor collar, fang,
astolfo,fate,solo, fate, pink eyes, cape, hair ribbon, crossdressing, looking at viewer, otoko no ko, solo, smile, braid, ribbonastolfo, fate, bow, yaoi, hair bow, looking at viewer, otoko no ko, multiple boys, erection, cum in ass, multiple
astolfo,fate,solo, fate, purple hair, bow, red skirt, red buruma, hair bow, looking at viewer, otoko no ko, solo, buruma, fang, skirt, braid, open mouth, fur collar, hood, blush, black bow, necklace, looking back, jewelry, navel, necktie,
一つ目は制服衣装でしょうかね?そんなに悪くないです。2つ目は途中で新しくastolfoから始まってしまいましたね。しかもよくない単語が続いてますね。3つ目はよく分かりません。ブルマなのかスカートなのか・・・
通常衣装
入力:astolfo,fate,solo,armor,gauntlets,
出力:
astolfo,fate,solo,armor,gauntlets,savel,s, greyscale, sweat, yaoi, bow, fur-trimmed cloak, looking at another, capelet, white thighhighs, multiple boys, gauntlets, chain, gauntlets, brown hair, short hair, thighhighs, fur-tr
astolfo,fate,solo,armor,gauntlets,red,hearts,sora,santa alter, fujimura taiga, merlin, aether, fate, chibi, swimsuit rider, fate/extra ccc, swimsuit lancer, male, fate/extra ccc, caster, outdoors, swimsuit lancer
astolfo,fate,solo,armor,gauntlets, underwear, sweat, yaoi, bow, hair bow, black panties, otoko no ko, gauntlets, midriff, hair ribbon, black thighhighs, thighhighs, long sleeves, fang, skirt, braid, open mouth, panties, blush, black bow
armorやgauntletsで通常衣装っぽいプロンプトが出てくると期待したんですが、うーんだめだこりゃ。
制服
入力:astolfo,fate,sailor paladin,
出力:
astolfo,fate,sailor paladin, bow, tail, official alternate costume, looking at viewer, otoko no ko, solo, pleated skirt, midriff, hair ribbon, thighhighs, red skirt, sailor collar, fang, skirt, braid, v, open mouth, serafuku, blush, black bow,
astolfo,fate,sailor paladin, underwear, bow, white shirt, hair bow, official alternate costume, looking at viewer, otoko no ko, solo, pleated skirt, midriff, hair ribbon, cheerleader, sailor collar, fang, skirt, braid, open mouth, panties, serafuku, blush, long
astolfo,fate,sailor paladin, underwear, thighhighs under boots, heart, bow, yaoi, official alternate costume, looking at viewer, otoko no ko, multiple boys, erection, multiple penises, pleated skirt, clothes lift, hair ribbon, penises touching, thighhighs, penis, red skirt, sailor
1つ目は問題なさそうです。ちゃんと制服を表すタグが生成されています。2つ目はチアリーダーが気になるけどおおむね問題なさそう。3つ目は、ちんちんちんちんちんって感じですねww
アポクリファ私服
入力:astolfo,memories at trifas,
出力:
astolfo,memories at trifas, fate, sparkling frills, flower, swimsuit, bow, hat, denim shorts, hair bow, official alternate costume, looking at viewer, otoko no ko, solo, bikini, hair bow, sunlight, off-shoulder bikini, toenails, beach, bracelet, fang, braid, open
astolfo,memories at trifas, fate, memories at trifas, purple footwear, striped shirt, miniskirt, bow, black skirt, hair bow, official alternate costume, looking at viewer, otoko no ko, solo, purple shirt, purple jacket, pleated skirt, midriff, pink sailor collar, sneakers, long sleeves,
astolfo,memories at trifas, open mouth, hair ribbon, closed eyes, nude, one eye closed, fang, looking at viewer, otoko no ko, smile, multiple boys, braid, ribbonastolfo, fate, bow, hair bow, looking at viewer, otoko no ko, solo, gauntlets, black thighhigh
1つ目はなぜか水着概念礼装が混じってしまいました。2つ目はよさそうとおもったら唐突にpink sailor collarが出てきてしまいました。3つ目はうーん?
セイバー衣装一臨
入力:astolfo,saber,first ascension,
出力:
astolfo,saber,first ascension, fate, bed sheet, underwear, bow, hair bow, black panties, looking at viewer, otoko no ko, solo, bed, animal ears, hair ribbon, black thighhighs, thighhighs, lying, fang, white panties, braid, upskirt, from above, thighs, panties
astolfo,saber,first ascension, arms up, heart, bow, bowtie, hair bow, looking at viewer, otoko no ko, multiple boys, black shirt, black gloves, thighhighs, long sleeves, fang, elbow gloves, open mouth, 2boys, blush, black bow, shirt, faulds, black ribbon,
astolfo,saber,first ascension, fate, sailor paladin, underwear, miniskirt, bow, black skirt, striped panties, hair bow, official alternate costume, looking at viewer, otoko no ko, red hair, symbol-shaped pupils, pleated skirt, midriff, cowboy shot, clothes lift, hair ribbon, thighhighs
うーんちょっと微妙ですね。1つ目でanimal earsがでたり2つ目でblack bowが出たりとまあまあセイバー衣装っぽさはありますが。
セイバー衣装最終再臨
入力:astolfo,saber,third ascension,
出力:
astolfo,saber,third ascension, bed sheet, saber, first ascension, tongue, bow, bowtie, hair bow, looking at viewer, otoko no ko, solo, hair ribbon, black gloves, hair ribbon, long sleeves, black bowtie, tongue out, pantyhose, black dress, black bowtie, skirt,
astolfo,saber,third ascension, greyscale, twintails, bow, hair bow, looking at viewer, otoko no ko, solo, smile, v, forehead, multiple boys, animal ears, hair ribbon, fang, braid, sketch, gloves, ribbonastolfo, fate, bow, hair bow, looking at viewer
astolfo,saber,third ascension, arms up, fate, bow, bowtie, hair bow, looking at viewer, otoko no ko, solo, hair ribbon, black gloves, long sleeves, one eye closed, black bowtie, fang, black dress, wing collar, dress, blush, black bow, black ribbon, low twintails
dressといった最終再臨特有のタグが出てきますが、結構後ろになってしまいますね。これは学習データのせいかもしれません。
面白事例
入力:astolfo,saber,memories at trifas,
出力:astolfo,saber,memories at trifas, artoria pendragon, fate, swimsuit rider, first ascension, swimsuit saber, injury, swimsuit, bow, tentacles, hairband, looking at viewer, otoko no ko, bikini, yellow eyes, 1girl, hair ribbon, cleavage, thighhighs, fang
入力ミスったおかげで発見したのですが、saberとmemories at trifasは通常並ぶことがないタグです。しかしアルトリアのキャラクタータグにもsaberがあるので、AIがsaberとmemories at trifas両方があるということは、このsaberはアルトリアのことなんだ!と類推しているようです。すごーい。
課題
nsfwは分ける必要がありそうです。また今回初めてやったことなので設定とかよく分かりません。検証用データも作ってないですしね。
半年前に自分で作った機械学習によるオセロAIの復習をする4
前回はモンテカルロ木探索について適当に紹介しました。今回は学習編です。学習といっても難しいことはしません。単にAI同士で対局したデータを集める⇒ネットワークに学習させる⇒以下ループ、するだけです。ただAI同士の対局では同じ手ばっかり指し手も意味ないので、一定確率で次善手やランダムな手を指すようにしています。
対局データは、(盤面,指し手,最終的な結果,評価値)を何万局といった単位で生成したものになります。
最終的な結果は勝敗の2値ではなく石数の差をシグモイド関数で0から1に変換したものになります。
損失関数は、
- 方策ネットワークは実際の指し手(64次元ベクトル)と予測した指し手(64次元ベクトル)の交差エントロピー誤差(※実際の指し手はone hotベクトルなので、実質log1個だけ)
- 価値ネットワークは最終的な結果(1次元ベクトル)と予測した評価値(1次元ベクトル)の二値交差エントロピー誤差
この二つの誤差を単純に足して、モーメンタム付きのSGDで最適化します。
ただし、途中までこの方法でやっていましたが、方策ネットワークは前世代の指し手を模倣するだけで、対局結果は考慮していません。
そこで方策ネットワークの誤差にActor critic法を使います。前世代の対局データがActor、前世代の価値ネットワークがcriticになります。
Actor Critic版誤差
評価値が悪かったのに勝ったら大きくなり、評価値が良かったのに負けたら小さくなります。これにより良い手はよりよく学ぶようになり、悪い手は反面教師にできるようになります。0.5を足しているのは山岡さんによると前世代のAIが考えた指し手なのだからある程度信頼するべきだからだそうです。本家のActor criticでは0.5を足したりしませんが、足さないで試しましてみると結果はよくなかったです。
価値ネットワークの誤差も改良します。ブートストラップという方法を使います。これは自分のネットワークを自分自身で改良するという方法で、まあ数式にすると、
です。
bceは二値交差エントロピーです。
前の世代の価値ネットワークも参考にするということですね。何でこうしてるかは忘れました。
実装、面倒なのでlossの計算だけ。データセットを用意したりオプティマイザーを用意するなどは普通の深層学習と変わりません。
dataが盤面、policyが指して(one hotベクトル)、valueが結果、evalが評価値です。
output1が方策ネットワークの出力、output2が価値ネットワークの出力です。
output1,output2 = model(data) //sumを使っているが実際には1個以外全部0 loss_p = torch.sum(- policy * F.log_softmax(output1,dim=1),1) z = value - eval + 0.5 loss_p = (loss_p * z).mean() loss_p += (F.softmax(output1, dim=1) * F.log_softmax(output1, dim=1)).sum(dim=1).mean() loss_v = loss_bce(output2,value) loss_e = loss_bce(output2,eval) loss = loss_p + loss_v * 0.7 + loss_e * 0.3
学習結果
世代ごとの説明、19世代でactor critic、25世代で完全読みを実装してます。
| 自己対局 | epoch | |
|---|---|---|
| 第一世代 | 1万局のランダム対戦 | 82 |
| 第二世代 | 1万局の2手読みαβ探索 | 100 |
| 第三世代 | 1万局の2手読みαβ探索 | 100 |
| 第四世代 | 1万局の2手読みαβ探索 | 100 |
| 第五世代 | 1万局の2手読みαβ探索 | 100 |
| 第六世代 | 1万局の100playoutMCTS | 100 |
| 第七世代 | 1万局の100playoutMCTS | 100 |
| 第八世代 | 6000局の100playoutbat8MCTS + 4000局の100playoutMCTS | 100 |
| 第九世代 | 1万局の100playoutbat8MCTS | 100 |
| 第十世代 | 1万局の100playoutMCTS | 20 |
| 第11世代 | 1万局の100playoutMCTS | 20 |
| 第12世代 | 1万局の100playoutMCTS | 20 |
| 第13世代 | 1万局の100playoutMCTS | 20 |
| 第14世代 | 1万局の100playoutMCTS | 20 |
| 第15世代 | 1万局の300playoutMCTS | 20 |
| 第16世代 | 4万局の100playoutMCTS | 20 |
| 第17世代 | 6万局の100playoutMCTS | 20 |
| 第18世代 | 8万局の100playoutMCTS | 20 |
| 第19世代 | 32000局の100playoutMCTS | 60 |
| 第20世代 | 40000局の500playoutMCTS | 60 |
| 第21世代 | 40000局の500playoutMCTS+前世代 | 60 |
| 第22世代 | 40000局の500playoutMCTS+前世代+前々世代 | 60 |
| 第23世代 | 40000局の500playoutMCTS+前世代+前々世代 | 60 |
| 第24世代 | 80000局の800playoutMCTS+前世代+前々世代 | 80 |
| 第25世代 | 134000局の1000playoutMCTSp10 | 70 |
| 第26世代 | 82000局の1000playoutMCTSp10+前世代 | 60 |
| 第27世代 | 120000局の1000playoutMCTSp10+前世代 +前々世代 | 60 |
最初はランダム探索で、その後方策ネットワークだけでαβ探索により教師データを作成していました。モンテカルロ木探索を実装してからはプレイアウトを増やしたり対局数をどんどん増やしていって27世代までやりました。
勝率比較
個人的にやってたのですごいわかりづらいですが、genは世代、haltはプレイアウト数、batは未評価ノードをvirtul lossにして、蓄積する回数、pは完全読みの手数です。
| 勝ち | 負け | 引き分け | ||
|---|---|---|---|---|
| 第10世代 | ||||
| gen10/halt100/ bat8/epoch20 | gen1/halt100/bat8 | 98 | 2 | 0 |
| gen2/halt100/bat8 | 99 | 1 | 0 | |
| gen3/halt100/bat8 | 95 | 5 | 0 | |
| gen4/halt100/bat8 | 91 | 9 | 0 | |
| gen5/halt100/bat8 | 89 | 10 | 1 | |
| gen6/halt100/bat8 | 81 | 16 | 5 | |
| gen7/halt100/bat8 | 80 | 18 | 2 | |
| gen8/halt100/bat8 | 82 | 15 | 3 | |
| gen9/halt100/bat8 | 82 | 17 | 1 | |
| 第20世代 | ||||
| gen20/halt100/bat8 | gen19/halt100/bat8 | 175 | 121 | 4 |
| gen18/halt100/bat9 | 184 | 109 | 7 | |
| gen17/halt100/bat10 | 184 | 104 | 12 | |
| gen16/halt100/bat11 | 223 | 70 | 7 | |
| 第24世代 | ||||
| gen24/halt100/bat8/p4 | gen23/halt100/bat8/p4 | 159 | 131 | 10 |
| gen22/halt100/bat8/p4 | 173 | 117 | 10 | |
| gen21/halt100/bat8/p4 | 191 | 101 | 8 | |
| 第27世代 | ||||
| gen27/halt500/bat8/p8 | gen24/halt500/bat8/p8 | 170 | 120 | 10 |
| gen25/halt500/bat8/p8 | 150 | 142 | 8 | |
| gen26/halt500/bat8/p8 | 143 | 148 | 9 |
自己対局ばっかりで実際どれほどの強さか分かりにくいですが、私はオセロのこと全然分からないので実際によく分からないです。ただしその辺の無料オセロゲームは相手にならないです。
またEgaroucidのレベル5くらいに(こちらの方が30倍くらい読む時間長いですが^^)勝てます。
学習で分かったこと
10世代の結果を見た通り1世代どころか9世代にすら勝率ばくあがりしています。これはエポックを100から20に下げたからです。どうして下げるとよくなったかというと、学習が進むとある点で価値ネットワークの精度はあがるけど、方策ネットワークの精度は下がっていくようになります。lossを足し合わせているので、そういうことが起きてしまうのですね。おそらくそれが原因でlossは減ったのに弱くなるといったことが起こったのだと思います。学習しまくればいいってもんでもないんですね。
私の実装ではvirtual lossはあまり意味ないようです。virtual lossはgpuの並列計算能力を生かすために、未評価のノードの評価を保留して、とりあえず評価値に0を代入しておき、未評価ノードがたまったらいっきに評価する手法です。gpuの計算効率はあがるのですが、探索精度は下がります。Deepmindや山岡さんが実装しているAIはネットワークが非常に大きいので計算時間のほとんどがGPUです。それに対して私がやっているAIはネットワークがそこまで大きくないのに対して、探索部分はPythonで並列処理なしで実行しているため、CPU部分の計算時間の割合が結構大きいです。そのためGPUの計算時間削減が探索精度の低下に見合っていません。
おわり
RTX3090買ったので、Stable diffusionの学習や画像生成の所要時間をNVIDIA GPUごとに比較してみた
今週のお題「買ってよかった2022」
↑なんか書こうとしてた記事とぴったりだったのでいれておく^^いやでもこれって複数の商品を紹介するのかな?
RTX3090を買ったので、Paperspace gradient(参考)のFree-GPU達と比較してみます。
元々Ryzen 5 5600X+RTX3070ti+メモリ32GBでしたが、VRAM足らないのが我慢できなくて3090に換装しました。4090搭載のbto pcとかを思い切って買っちゃおうかとかも考えましたが、VRAM以外に不満はなかったし、作ってから1年ちょっとしかたってないので、がんばって電源とともに付け替えました。ゲーム性能だけみたら4080の方がコスパよさそうですが、機械学習のことを考えたらVRAM24GBあった方ができること増えていいですよね。VRAM24GBのGPUが17万円で買えるなんて3090が出回ってる今を逃したら当分なさそうですしね。
画像生成
私は学習時間に興味があったのですが、画像生成の方が需要ありそうなのでそちらから。A100は空いたら追加します(した)。
webuiでStable diffusion 2.0系のモデルに768×768画像を64枚生成させてみます。(50stepsでxformersあり)
| batch size | 所要時間 | 1枚にかかる秒数 | |
| A100 80GB | 64 | 135 | 2.11 |
| A6000 | 32 | 240 | 3.75 |
| A5000 | 16 | 327 | 5.11 |
| RTX3090 | 32 | 302 | 4.72 |
A100最強!
真ん中二つはbatch sizeが大きすぎるとなぜかbatch count2個目からcuda out of memoryになります(GPUではなく環境の問題だと思いますが)。ただA5000ではbatch sizeをあげても効率がかわらなかったので、RTX3090の方が強いみたいですね。さすがにA6000には勝てませんが、値段全然違うしこっちはゲームもできますからね。

学習
次にStable diffusion2.0の学習を同じデータセット(768×768)でやってみます。バッチサイズとGradient Checkpointing有無を変えながらやってみました。RTX3090だけローカルでやってるので公平な比較ではないかもしれません。一応CPUやメモリ側がボトルネックになっている感じではなさそうですが、ようつべみながらやってたのでww(CPUがビデオカードなしなんだよね)VAEによる潜在変数の計算は予めやっているので、VAEの計算時間は入っていません。
samples/sが1秒ごとに学習できる画像枚数です。
| batch size | grad checkpoint | steps/s | samples/s | ||
| A100 80GB | 128 | 1 | 0.09 | 11.93 | |
| 64 | 1 | 0.18 | 11.66 | ||
| 20 | 0 | 0.69 | 13.89 | ||
| 16 | 0 | 0.79 | 12.6 | ||
| A6000 | 64 | 1 | 0.1 | 6.4 | |
| 12 | 0 | 0.58 | 6.98 | ||
| 8 | 0 | 0.85 | 6.78 | ||
| A5000 | 20 | 1 | 0.23 | 4.66 | |
| 16 | 1 | 0.28 | 4.41 | ||
| 3 | 0 | 1.25 | 3.75 | ||
| 2 | 0 | 1.47 | 2.94 | ||
| RTX3090 | 16 | 1 | 0.25 | 4 | |
| 2 | 0 | 1.11 | 2.22 |
A100最強!
プロ向けのGPU達には敵いませんが、A5000に引けを取らない結果がでてますね。VRAMがA5000とRTX3090では同じなので、理論上は同じ設定でできるはずですが、バッチサイズ20(grad checkpoint有)などではCUDA out of memoryしました。ようつべとかみてるからかも・・w
あと新たな発見として、VRAMが小さいA5000やRTX3090ではgradient checkpointingを利用してバッチサイズを大きくしたほうが良いということが分かりました。
換装した感想
正直月額5000円ちょっとでA5000~A100を使えるサービスがあるのに、わざわざ17万円と電気代を払う必要があるのかという感じもするのですが、Paperspaceでは容量の問題や制限時間のために大規模データセットで学習しづらいなあと感じていました。ですがA100の3分の1以下の学習能力と考えるとそこまでの規模の学習は難しそうですね。画像生成に関しては、Paperspaceでwebuiを使う場合、あまり応答がよくないgradioのwebアプリを利用しなければいけないので、ローカルで使えるRTX3090は役立ちそうです。そもそもngrokを使ったら停止されちゃったので、同じようなものであるgradioの共有機能を使うのはよくないかもしれません。
ちなみにゲームはまだやってないです。持ってるモニターが2Kの144HzだしCPUが3090に比べると弱いのでゲーミング性能的には恩恵なさそう・・・。モニター以前に私の瞳は30Hzまでしか対応してないですけどね。
半年前に自分で作った機械学習によるオセロAIの復習をする3
前回はネットワークを紹介しました。このネットワークは指し手(方策)と評価値(価値)を返します。このネットワークを利用して、モンテカルロ木探索という手法により、実際の指し手を計算していきます。
モンテカルロ木探索というと、なんだかランダム性がありそうな予感がしてきますが、なんと決定的なアルゴリズムです。元々のモンテカルロ木探索は、でたらめに試行しまくってたまたま一番勝率が高かった手を選ぶという手法です。ランダムな試行でもゲームが終わる囲碁で流行した手法のようです。機械学習を利用する文脈ではネットワークに基づいて試行していくため、ランダム性はありません。じゃあ名前変えろよって思っちゃいません?方策価値ネットワーク木探索とかどうですか。
ここからの説明は元のモンテカルロ木探索に関する知識がないとイメージしづらいかと思います。聖書を読んでください。
オセロとか将棋とかは局面をノード、指し手をエッジとすると、木になります。現在の盤面から指し手を探索していって、木をどんどん大きくしていきます。木をおっきくすれば良い手が見つけやすくなりそうですね。
モンテカルロ木探索の一回分の探索単位をプレイアウトと呼びます。1プレイアウトでは、根から初めてひたすら子ノードをもぐっていき、葉っぱにたどりつくまで探索します。深さ優先探索みたいな感じで、隣のノードを探索したりしません。探索経路はいっぱいありますが、3つの基準で決めます。
- 方策ネットワークに基づく指し手の確率(大きいほど、選ばれやすい)
- 価値ネットワークに基づく葉ノードの平均評価値(大きいほど、選ばれやすい)
- 訪問回数(大きいほど、選ばれにくい)
1は分かりやすいですね。ネットワークが良い手を予測してくれると仮定すれば、その手を探索すればいいわけです。2ではそのノードからたどり着く葉ノードの平均評価値(価値ネットワークの出力)に基づいています。読み進めていくと意外といい手だった、なんて場合に良い結果になります。1,2について、ネットワークは常に同じ値を示すので、それだけでは何回探索しても同じ経路をたどるだけです。そこで3の出番です。訪問回数が大きいほど、十分探索できたでしょ、という考えで探索経路に選ばれづらくします。こうすることで、良い手ほどいっぱい探索されて、そうでもない手はあまり探索されません。
具体的にはあるノードにたどり着いたとき、以下が一番高い子ノードが次の探索先になります。
葉にたどり着いたら、葉の訪問回数が規定値より大きければ、合法手分ノードを展開して、木を大きくします。
というわけでプレイアウトを複数回やることで、木を成長させて最終的には葉ノードの平均評価値が一番高いノード(根の子ノード)が指し手として選ばれます。指し手を決める部分では、価値ネットワークに基づく評価値のみを参照するんですね。指し手を予測する方策ネットワークの出力は探索のみに使われます。この辺直感に反しますね。
これが全体的な流れですが、プレイアウト中にノードが展開され、新しいノードにたどり着いたとき、その盤面をネットワークで推論することになります。1つ1つのノードに推論していくのは、GPUの並列処理ぱわーを生かせていません。そのため実際には1つ1つノードを推論するのではなく何回か探索して新しいノードがたまったら並列で推論する、という方法をとります。ただし何回探索しても同じノードにたどり着いてしまったら意味がありません。そこで推論前のノードはとりあえず評価値を0(Virtual Loss)としておきます。評価値が0なので探索対象になりづらくなり、別の経路が選ばれるようになります。推論した後は、評価値を正しい値に直します。
以下実装を貼り付けるだけ。Pythonでやってますが、強いAIを作るためにはコンパイラ言語を利用したり、並列処理が必要です。
ノードクラスには、ネットワークの出力や、訪問回数、子ノードの情報や展開処理などが含まれます。
class Node(): def __init__(self,iniwin=0.5,node_test=False): self.move_count = 0 self.sum_value = 0.0 self.child_move = None self.child_move_count = None self.child_sum_value = None self.child_node = None self.policy = None self.value = None self.iniwin = 0.5 self.node_test = node_test def creat_child_node(self, index): self.child_node[index] = Node() def expand_node(self,board): child_num = len(self.child_move) self.child_move_count = np.zeros(child_num,dtype=np.int32) self.child_sum_value = np.zeros(child_num,dtype=np.float32) self.child_node = [None]*child_num def update(self,policy,value): self.policy = [policy[move%10 + move//10*8 -9].item() for move in self.child_move] self.value = value[0] def leaf(self,board): self.child_move = board.legal_moves if len(self.child_move)==0: self.value = sigmoid(board.turn * board.board[BOARD].sum()/10) return True return False def eval(self,board,model): self.child_move = board.legal_moves if len(self.child_move)==0: self.value = sigmoid(board.turn * board.board[BOARD].sum()/10) else: feature = np.array([board.feature()],dtype=np.float32) policy, value = self.infer(feature,model) self.value = value[0,0] self.policy = [policy[0][move%10 + move//10*8 -9].item() for move in self.child_move] def choice(self,c_puct): if self.node_test: win_rate = self.child_sum_value / (self.child_move_count+1) else: win_rate = np.divide(self.child_sum_value,self.child_move_count,out=np.zeros(len(self.child_move), np.float32)+self.iniwin,where=self.child_move_count != 0) index = np.argmax(win_rate + (self.policy * (np.sqrt(np.float32(self.move_count)) / (self.child_move_count + 1))) * c_puct) if self.child_node[index] == None: self.creat_child_node(index) return index
MCTSクラスでは、プレイアウト、バーチャルロスとバーチャルロスを元に戻すバックアップなどの処理があります。またオセロの場合、最終局面は全探索可能なので全探索して最善手を出します。
推論関数はonnxを利用しているのでちょっと特殊です。まあ指し手にソフトマックスを通して、評価にシグモイドを通しているだけです。
import time def infer(feature,session,batch=1): if session == "random": return np.random.rand(batch,64) , np.random.rand(batch,1) io_binding = session.io_binding() io_binding.bind_cpu_input('input', feature) io_binding.bind_output('policy') io_binding.bind_output('value') session.run_with_iobinding(io_binding) policy,value = io_binding.copy_outputs_to_cpu() return softmax(policy),sigmoid(value) class MCTS(): def __init__(self,board,session,halt=100,c_puct=1,threshold=3,batch_size=8,iniwin = 0.5,node_test = False,perfect=0,temp=0.1): self.original_node = Node(iniwin,node_test) self.original_board = board.copy() self.current_node = self.original_node self.current_board = board.copy() self.route = [] self.indexes = [] self.turns = [self.current_board.turn] self.moves = [] self.threshold = threshold self.playout_number = 0 self.session = session self.halt = halt self.c_puct = c_puct self.batch_size = batch_size self.current_batch = 0 self.batch_route = [] self.batch_feature = [] self.times = 0 self.iniwin = iniwin self.node_test = node_test self.perfect = perfect self.temp = temp def search(self,prob=False): self.times = 0 while self.playout_number <= self.halt: self.route.append(self.current_node) if self.current_node.move_count == 0: if self.current_node.leaf(self.current_board): self.playout() continue else: self.virtual_loss() continue elif self.current_node.value == None: self.virtual_loss(False) continue elif self.current_node.move_count < self.threshold: self.playout() continue else: if self.current_node.child_node == None: self.current_node.expand_node(self.current_board) if len(self.current_node.child_move) == 0: self.playout() continue index = self.current_node.choice(self.c_puct) self.moves.append(self.current_node.child_move[index]) start_time = time.perf_counter() self.current_board.move(self.current_node.child_move[index]) end_time = time.perf_counter() self.times += end_time-start_time self.current_node = self.current_node.child_node[index] self.indexes.append(index) self.turns.append(self.current_board.turn) sorted_index = np.argsort(self.original_node.child_move_count)[::-1] winrate = self.original_node.child_sum_value[sorted_index[0]] / self.original_node.child_node[sorted_index[0]].move_count if prob: move = np.random.choice(self.original_node.child_move,p=softmax([self.original_node.child_move_count/self.halt/self.temp])[0]) return move,winrate else: return np.array(self.original_node.child_move)[sorted_index] ,winrate def perfect_search(self,input_board): v = 0 max = -1000 turn = input_board.turn if len(input_board.legal_moves) == 0: return None,sigmoid(input_board.turn*input_board.board[BOARD].sum()/10) for move in input_board.legal_moves: board = input_board.copy() board.move(move) _,v = self.perfect_search(board) if turn != board.turn: v = 1 - v if v >= max: best_move = move max = v return best_move,max def move(self,num=0,re_eval=False,prob=False): if self.perfect >= 100 - np.count_nonzero(self.current_board.board): move,eval = self.perfect_search(self.current_board) else: if prob: move,eval = self.search(True) else: moves,eval = self.search() move = moves[min(num,len(moves)-1)] self.playout_number = 0 index = self.original_node.child_move.index(move) if self.original_node.child_node[index] == None: self.original_node = Node(self.iniwin,self.node_test) else: self.original_node = self.original_node.child_node[index] self.current_node = self.original_node self.original_board.move(move) self.current_board = self.original_board.copy() if re_eval: return move,eval else: return move def move_enemy(self,move): self.original_board.move(move) self.current_board = self.original_board.copy() self.playout_number = 0 if self.perfect >= 100 - np.count_nonzero(self.current_board.board): return; if self.original_node.child_node == None: self.original_node = Node(self.iniwin,self.node_test) else: index = self.original_node.child_move.index(move) if self.original_node.child_node[index] == None: self.original_node = Node(self.iniwin,self.node_test) else: self.original_node = self.original_node.child_node[index] self.current_node = self.original_node def playout(self): self.playout_number += 1 results = None while len(self.route) > 0: node = self.route.pop() if results == None: results = node.value node.sum_value += results else: index = self.indexes.pop() node.sum_value += results node.child_move_count[index] += 1 node.child_sum_value[index] += results turn = self.turns.pop() if len(self.turns) >= 1 and turn != self.turns[-1]: results = 1 - results node.move_count += 1 self.current_node = self.original_node self.current_board = self.original_board.copy() self.route = [] self.indexes = [] self.moves = [] self.turns = [self.current_board.turn] def virtual_loss(self,init=True): self.current_batch += 1 self.batch_route += [(self.route.copy(),self.indexes.copy(),self.turns.copy())] if init: self.batch_feature += [self.current_board.feature()] results = None while len(self.route) > 0: node = self.route.pop() if results == None: results = 0 else: index = self.indexes.pop() node.child_move_count[index] += 1 turn = self.turns.pop() node.move_count += 1 self.current_node = self.original_node self.current_board = self.original_board.copy() self.route = [] self.indexes = [] self.moves = [] self.turns = [self.current_board.turn] if self.current_batch == self.batch_size: self.backup() self.current_batch = 0 def backup(self): self.playout_number += self.current_batch policies, values = infer(np.array(self.batch_feature,dtype=np.float32),self.session,batch=len(self.batch_feature)) i = 0 for route,indexes,turns in self.batch_route: results = None while len(route) > 0: node = route.pop() if results == None: if node.value==None: results = values[i,0] node.update(policies[i],values[i]) i+=1 else: results = node.value node.sum_value += results else: index = indexes.pop() node.sum_value += results node.child_sum_value[index] += results turn = turns.pop() if len(turns) >= 1 and turn != turns[-1]: results = 1 - results self.batch_route = [] self.batch_feature = []
半年前に自分で作った機械学習によるオセロAIの復習をする2
前回の続きです。今回はネットワーク編です。機械学習というか深層学習により、次の手を判断するAIを作ります。前回同様将棋AIで学ぶディープラーニング | マイナビブックスを参考にしています。
ニューラルネットワークを利用した将棋AIといわれて私が最初にイメージしたのは、盤面をニューラルネットワークに入力すれば、出力として良い手が返ってくるようなものでした。しかし残念ながら1手も読まずに指し手を予測するだけでは、アマチュア強豪クラスの強さにしかならないそうです。そこで指し手に加えて盤面の有利不利を同時に予測します。指し手を予測するネットワークを方策ネットワーク、有利不利を予測するものを価値ネットワークといいます。方策ネットワークに基づいて、盤面を読み進めていきながら、最終的に価値ネットワークによって一番有利になると予測された手を指すことで、強いAIが作れます。詳しくは次の記事で紹介します。
方策ネットワークと価値ネットワークという二つのネットワークに分けましたが、実際には一つのネットワークが途中から分岐するような形になります。この章からPythonです。
私が実装したネットワークの全体像はこんな感じやね。batchnormやreluは省略してます。
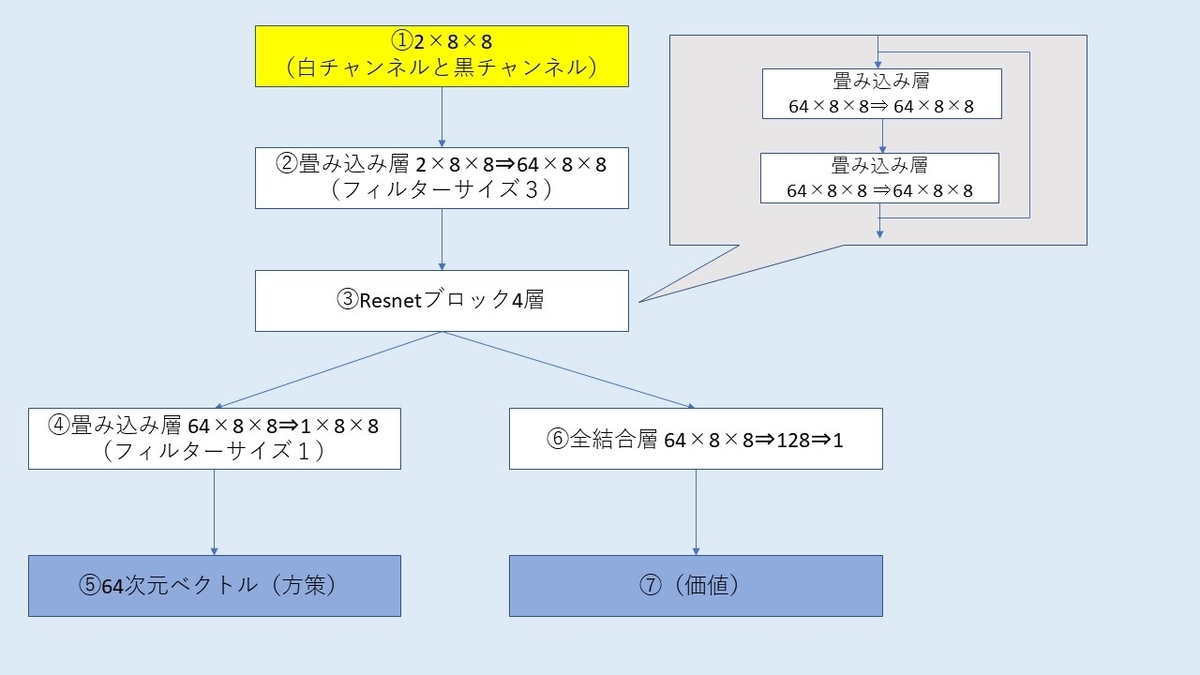
①入力はオセロの盤面8×8画像・・ではなく白と黒それぞれ1チャンネルで全部で2×8×8の画像になります。数値は1か0になりますね。今回は単純に盤面のみを入力するだけですが、上の本の場合は王手の情報や効きの情報などドメイン知識も入れています。オセロの場合でも、合法手の位置を示すようなチャンネルを加えるなどすれば精度があがりそうですが、今回はドメイン知識無しでどこまでできるか試したかったためそのような情報は入れていません。
②2チャンネルを64チャンネルに拡張する畳み込み層です。
③Resnetブロックが4層あります。Resnetブロックは2層の畳み込み層がありそれが4つ重なっているので8層の畳み込み層ですね。普通はプーリング層などで画像のサイズを半分にしてチャンネル数を増やす、みたいなことを繰り返すと思いますが、単なる画像認識と違って、オセロや将棋は1ピクセルの情報が非常に重要なので、圧縮はしません。しかしこれだと端から端まで情報が行き渡るのに時間がかかりますね。将棋の場合は飛車や角の利きが端っこまで届くのに、何層も必要ですが、途中で駒があった場合利きはなくなるのでむしろその方がいいのではみたいな感じのことをやねうらおさんがいってました。オセロも同じですね。将棋AIではずっとResnetがデファクトのようですが、もっといいネットワークがあったりしないかなあ。
④,⑤出力が8×8のベクトルになり、これが指し手の確率になります(そうなるよう学習します)。フィルターサイズ1なので、各マスに対して64個の重みづけ和をやっているだけですね。こういうのを畳み込みといっていいのでしょうか。
⑥,⑦全結合層で1次元ベクトルにするだけです。石の数の差を表します(そうなるよう学習します)。
ネットワークの実装です。全体構造さえ把握していれば、難しいことはないですね。
今になって気づきましたが、batchnormの前の層はbias=Falseしたほういいですね。
import torch import torch.nn as nn class ResNetBlock(nn.Module): def __init__(self, channels): super(ResNetBlock, self).__init__() self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) self.bn1 = nn.BatchNorm2d(channels) self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) self.bn2 = nn.BatchNorm2d(channels) def forward(self, x): out = self.conv1(x) out = self.bn1(out) out = torch.relu(out) out = self.conv2(out) out = self.bn2(out) return torch.relu(out + x) class PolicyValueNetwork(nn.Module): def __init__(self): super(PolicyValueNetwork, self).__init__() self.conv1 = nn.Conv2d(2, 64, kernel_size=3, stride=1, padding=1) self.norm1 = nn.BatchNorm2d(64) self.block1 = ResNetBlock(64) self.block2 = ResNetBlock(64) self.block3 = ResNetBlock(64) self.block4 = ResNetBlock(64) self.p1 = nn.Conv2d(64,1,kernel_size=1,stride=1,padding=0) self.v1 = nn.Linear(64*64, 128) self.v2 = nn.Linear(128, 1) def forward(self, x): x = self.norm1(self.conv1(x)) x = torch.relu(x) x = self.block1(x) x = self.block2(x) x = self.block3(x) x = self.block4(x) policy = self.p1(x) policy = torch.flatten(policy,1) value = torch.flatten(x, 1) value = self.v1(value) value = torch.relu(value) value = self.v2(value) return policy,value