半年前に自分で作った機械学習によるオセロAIの復習をする2
前回の続きです。今回はネットワーク編です。機械学習というか深層学習により、次の手を判断するAIを作ります。前回同様将棋AIで学ぶディープラーニング | マイナビブックスを参考にしています。
ニューラルネットワークを利用した将棋AIといわれて私が最初にイメージしたのは、盤面をニューラルネットワークに入力すれば、出力として良い手が返ってくるようなものでした。しかし残念ながら1手も読まずに指し手を予測するだけでは、アマチュア強豪クラスの強さにしかならないそうです。そこで指し手に加えて盤面の有利不利を同時に予測します。指し手を予測するネットワークを方策ネットワーク、有利不利を予測するものを価値ネットワークといいます。方策ネットワークに基づいて、盤面を読み進めていきながら、最終的に価値ネットワークによって一番有利になると予測された手を指すことで、強いAIが作れます。詳しくは次の記事で紹介します。
方策ネットワークと価値ネットワークという二つのネットワークに分けましたが、実際には一つのネットワークが途中から分岐するような形になります。この章からPythonです。
私が実装したネットワークの全体像はこんな感じやね。batchnormやreluは省略してます。
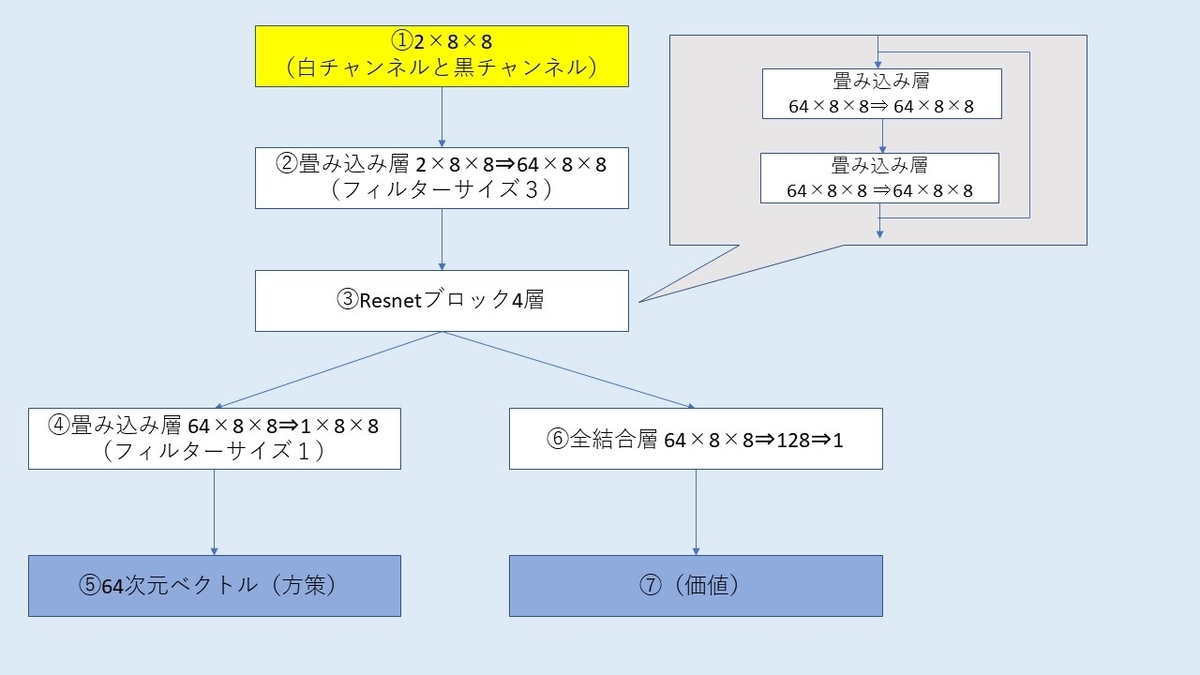
①入力はオセロの盤面8×8画像・・ではなく白と黒それぞれ1チャンネルで全部で2×8×8の画像になります。数値は1か0になりますね。今回は単純に盤面のみを入力するだけですが、上の本の場合は王手の情報や効きの情報などドメイン知識も入れています。オセロの場合でも、合法手の位置を示すようなチャンネルを加えるなどすれば精度があがりそうですが、今回はドメイン知識無しでどこまでできるか試したかったためそのような情報は入れていません。
②2チャンネルを64チャンネルに拡張する畳み込み層です。
③Resnetブロックが4層あります。Resnetブロックは2層の畳み込み層がありそれが4つ重なっているので8層の畳み込み層ですね。普通はプーリング層などで画像のサイズを半分にしてチャンネル数を増やす、みたいなことを繰り返すと思いますが、単なる画像認識と違って、オセロや将棋は1ピクセルの情報が非常に重要なので、圧縮はしません。しかしこれだと端から端まで情報が行き渡るのに時間がかかりますね。将棋の場合は飛車や角の利きが端っこまで届くのに、何層も必要ですが、途中で駒があった場合利きはなくなるのでむしろその方がいいのではみたいな感じのことをやねうらおさんがいってました。オセロも同じですね。将棋AIではずっとResnetがデファクトのようですが、もっといいネットワークがあったりしないかなあ。
④,⑤出力が8×8のベクトルになり、これが指し手の確率になります(そうなるよう学習します)。フィルターサイズ1なので、各マスに対して64個の重みづけ和をやっているだけですね。こういうのを畳み込みといっていいのでしょうか。
⑥,⑦全結合層で1次元ベクトルにするだけです。石の数の差を表します(そうなるよう学習します)。
ネットワークの実装です。全体構造さえ把握していれば、難しいことはないですね。
今になって気づきましたが、batchnormの前の層はbias=Falseしたほういいですね。
import torch import torch.nn as nn class ResNetBlock(nn.Module): def __init__(self, channels): super(ResNetBlock, self).__init__() self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) self.bn1 = nn.BatchNorm2d(channels) self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) self.bn2 = nn.BatchNorm2d(channels) def forward(self, x): out = self.conv1(x) out = self.bn1(out) out = torch.relu(out) out = self.conv2(out) out = self.bn2(out) return torch.relu(out + x) class PolicyValueNetwork(nn.Module): def __init__(self): super(PolicyValueNetwork, self).__init__() self.conv1 = nn.Conv2d(2, 64, kernel_size=3, stride=1, padding=1) self.norm1 = nn.BatchNorm2d(64) self.block1 = ResNetBlock(64) self.block2 = ResNetBlock(64) self.block3 = ResNetBlock(64) self.block4 = ResNetBlock(64) self.p1 = nn.Conv2d(64,1,kernel_size=1,stride=1,padding=0) self.v1 = nn.Linear(64*64, 128) self.v2 = nn.Linear(128, 1) def forward(self, x): x = self.norm1(self.conv1(x)) x = torch.relu(x) x = self.block1(x) x = self.block2(x) x = self.block3(x) x = self.block4(x) policy = self.p1(x) policy = torch.flatten(policy,1) value = torch.flatten(x, 1) value = self.v1(value) value = torch.relu(value) value = self.v2(value) return policy,value