こんかいはー、DDSP-SVCがどんな感じか見てみたのでメモしておきます。RVCに対するメリットデメリットなども考察していきます。
実装は以下を参考にしました。
github.com
全体像
DDSP-SVCは拡散モデルベースの音声変換モデルです。HuBERT特徴量・基本周波数(ピッチ)・音量・話者IDを条件としてメルスペクトログラムを生成します。音声波形の生成には学習済みのHiFi-GANなるものを使っているようです。音声変換時は画像生成(Stable diffusionとか)のときにimg2imgと呼ばれているような構造を使います。

訓練時は時刻までステップごとにランダムに選び、時刻に応じてノイズを加えてそれを予測するように学習します。音声変換時は時刻
を選んで、
のノイズ除去ループを実行して最終的に時刻
の状態を得ます。ただしループは1個ずつではなく、何個かスキップしながら実行します。図中のノイズ除去ループ部分はイメージがつきやすいDDPMによる実装になってますが、実際にはサンプラーによって違います。
モデル構造
WaveNetを元にした構造のモデルになります。
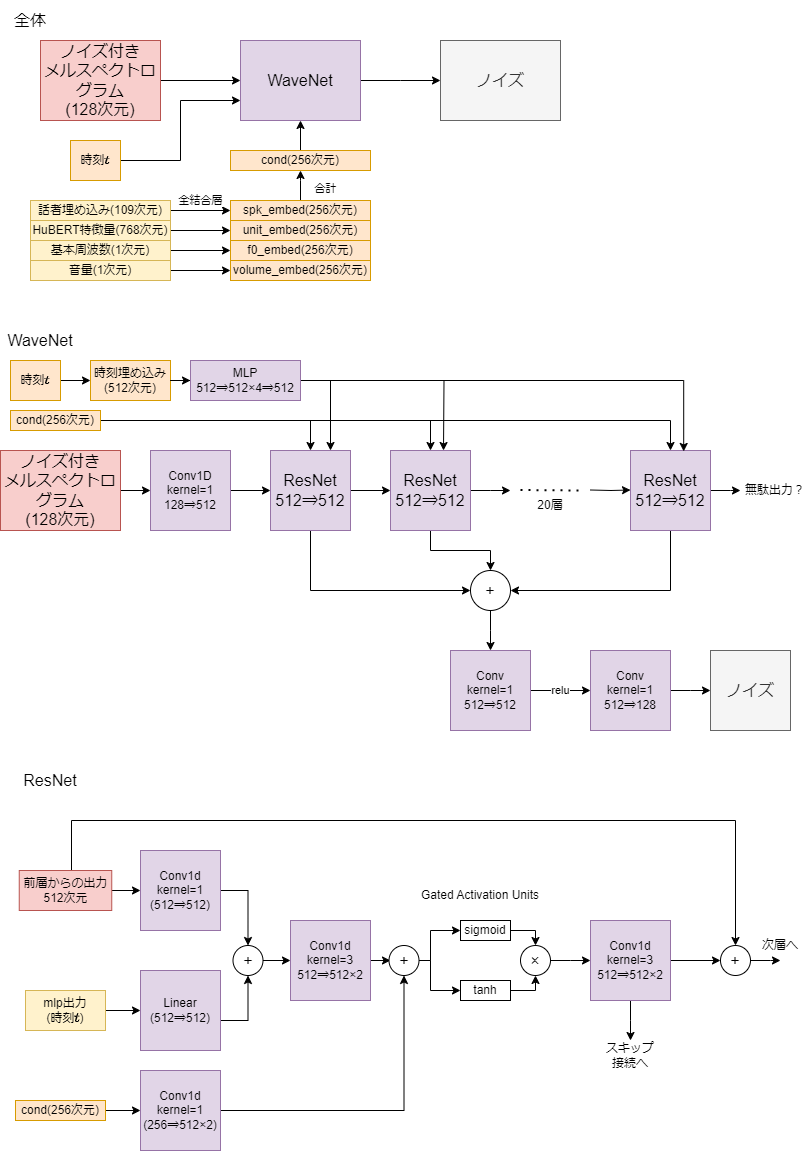
ResNetが20層のWaveNetになっています。ただしWaveNetと違って膨張畳み込みは使わず(dilation=1)、因果的な畳み込み(過去の情報のみを使う畳み込み)でもないです。VITSもそうでしたが、単なる畳み込みで十分なのかな?あと時刻埋め込みと条件埋め込みでは入力される場所が少し違いますが、この辺の違いは何を意味しているんでしょうかね?
訓練
訓練対象のモデルは、WaveNetと各条件を埋め込む全結合層のみとなります。HiFi-GANは学習しません。色々なモジュールを学習するRVCと違ってかなりわかりやすいですね。しかもRVCは推論時に使わないモジュールを学習する必要があったりと面倒です。ただしRVCは音声波形を生成するGAN部分まで学習しますが、DDSP-SVCはメルスペクトログラムを生成する部分までしか学習しません。その辺がどのくらい影響を与えるんでしょうかね。まあDDSP-SVCだってGANを学習してもいいんでしょうが。
時刻いくつまでを学習するかを設定する項目(k_step_max)があるみたいです。DDSP-SVCではノイズ除去は途中からしか行わないので、全ステップ学習する必要性はなさそうですね。
推論
全体像で書いた通り、変換したい音声のメルスペクトログラムに一定のノイズを加え、そこからノイズ除去することによって音声を変換します。画像生成モデルと同様に、推論時は時刻をある程度スキップします。
設定項目としてk_stepとspeedupがあります。名前は上のリンクにあるPipelineにしたがっています。k_stepは初期時刻をいくつにするかという項目で、Stable diffusion的にいうと、がDenoising strengthになります。speedupは時刻をどれだけスキップするかの項目で、
がsampling stepになります。またサンプラーは画像生成モデルでも見たことがあるやつが設定できますね。
DDSP-SVCのすごいと思われるところ
DDSP-SVCがすごいと思うのは、以下の2点です。
1. 精度と速度のトレードオフを調整できる
推論時に時刻をどのくらいスキップするかを設定することで、精度と速度を調節できます。音声変換の場合はリアルタイムで行いたいときは速度重視、そうでないときは精度重視、などと設定することができます。またGPU性能に応じて変更することもできますね。
2. 元の音声に対する忠実度と変換先の音声に対する精度を調整できる
入力した音声にどのくらいノイズを与えるかで、変換の強さを調整することもできます。これもかなり使えそうですよね。
RVCでも前者は検索対象の特徴量を制限したり、後者は線形補間の係数を調整することで同じようなことができそうではありますが、DDSP-SVCほど正確には調整できなそうな気がします(多分)。
DDSP-SVCで気になるところ
1. Classifier Free Guidanceを使ってない
DDSP-SVCではCFGを使っていません。画像生成モデルでもノイズの少ない状況ではCFGはあまり意味がないということが分かっているので、img2img(というかaudio2audio?)しかしないDDSP-SVCには必要ないのかもしれません。適用したら精度が良くなるのか気になりますが、計算量が2倍になるので結局実用性もなさそうです。というかそもそも無条件の埋め込みって何を入力したらいいんだ?
2. LoRAを使えるのか
LoRAは画像生成モデルと同様に実装できますが、どのくらいの精度でできるのか気になりますね。ただLoRAを適用するほどモデルが大きくなさそうなのと、話者IDによって複数話者対応のモデルを作れることから、そこまで意味がないのかも?
3. 最後のResNetブロックの出力が無駄になっている
ResNetブロックは次層への入力と最終出力へのスキップ接続の二つを出力しますが、最後のResNetブロックには次層なんてありません。それにもかかわらず次層への入力も出力する形になっているようです。そこまで変わらないと思いますが、ちょっと無駄ですね。
実装をみてみると、最終層のxが無駄になっていますよね。Diff-SVCから受け継がれたもののようですが。
for layer in self.residual_layers: x, skip_connection = layer(x, cond, diffusion_step) skip.append(skip_connection) x = torch.sum(torch.stack(skip), dim=0) / sqrt(len(self.residual_layers))
DDSP-SVCが弱そうなところ
RVCと違って、HuBERT特徴量から話者情報を変換する機構がありません。そのため話者情報に依存するようなHuBERTモデルだとうまくいかなそうな気がします。ただRVCの似た特徴量を検索して線形補間をとるやつってDDSP-SVCにも適用できるので、それをすればもっと精度あがったりするのかも??
おわりに
ここまで偉そうに語っておいて、使ったことないから実際の性能がどうなのか分からないです。ただ各設定項目の意味が割と分かってきたので、試してみる気になってきました。