VITS学習メモ
このメモは以下の記事をある程度読んだ上で、自分が戸惑ったところなどを補完するためのものです。私以外が読んで理解の助けになるのかよく分かりません。そもそも間違っているかもしれません。書いてみると理解できていないところがよく分かっていいですね。というわけで分からんところは分からんって書きます。
参考記事:
【機械学習】VITSでアニメ声へ変換できるボイスチェンジャー&読み上げ器を作った話 - Qiita
参考コード:
https://github.dev/zassou65535/VITS
はじめに
各変数(潜在変数とか潜在表現とか)が何を意味しているのか分かりづらかったので、モジュールではなく変数に着目する形で図式化してみましたあ。
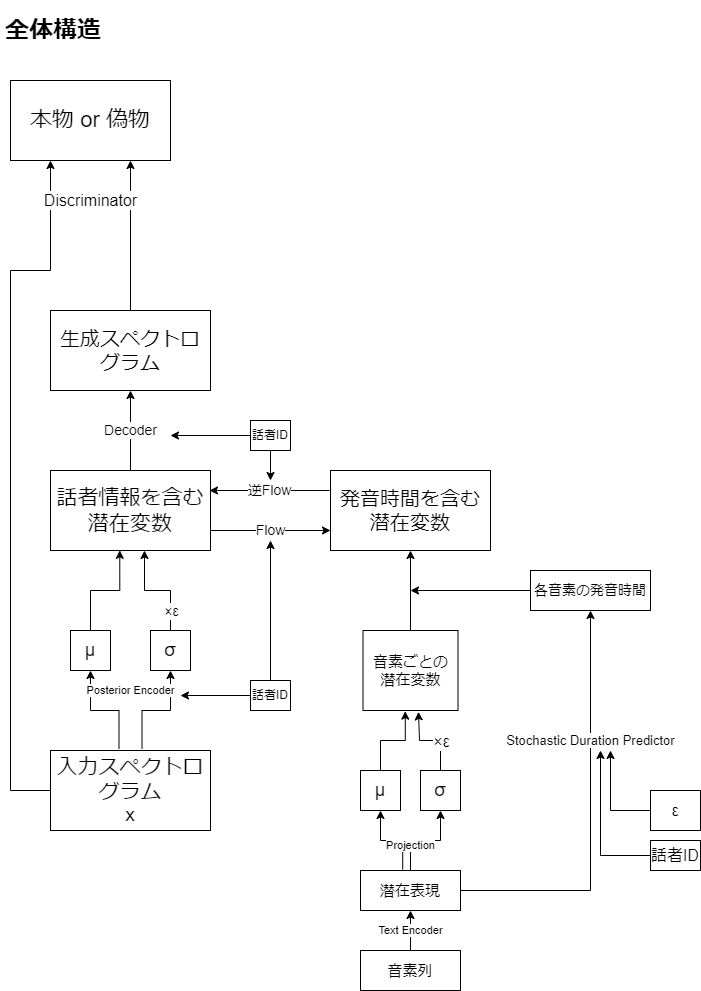
全体のイメージ図を描いただけで、実際にこのフロー通りに使われることはありません。
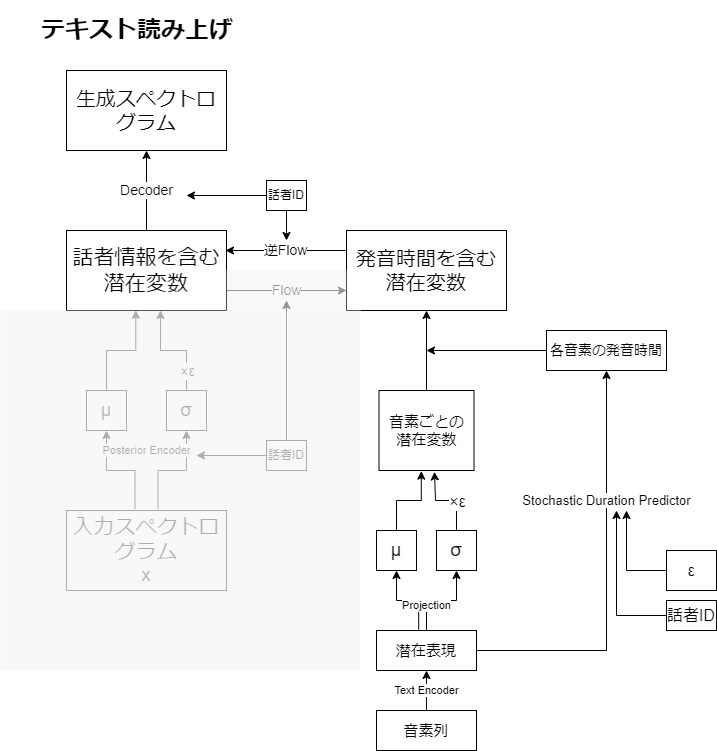
流れ自体は難しいことなさそうです。

Flowによって話者情報を入れ替えています。
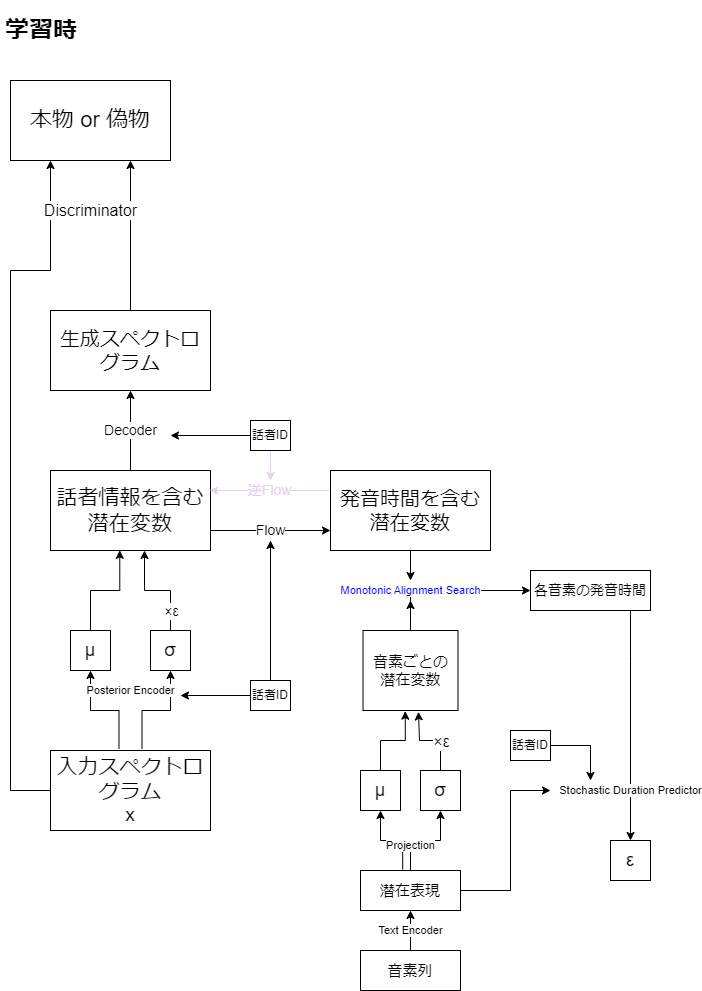
学習時は、Stochastic Duration Predictorの学習のため、各音素の発音時間を予測する必要があります。そのためにMonotonic Alignment Searchと呼ばれる手法を使っています。ここは学習パラメータがないので青文字にしています。
各モジュールの説明
私が最初に戸惑った原因として、VAEをEncoderとDecoderの組として、他のモジュールを切り離して考えてしまったことがあげられます。実際には事後分布を近似する、Posterior Encoder(事後エンコーダ)とテキスト条件付き事前分布
を近似するPrior Encoder(事前エンコーダ)、潜在変数が与えられたときの実際の音声分布
を近似するDecoder(デコーター)の三組からなるConditional VAEというアーキテクチャになっています。
- Posterior Encoder
スペクトログラムから潜在変数の平均と分散をだします。ネットワークにはWAVEGLOWというモデルで使われた構造がいくつか重なってできているようです(分かってない)。また話者IDも埋め込みベクトルに変換されて入力されます。Diffusion ModelのTime embeddingと同じで話者ごとにモデルを作らなくてもいいようにするということでしょうか。
- Text Encoder
テキストによる音素(謎のアルファベット列)を潜在表現に変換します。Transformerっぽいネットワークを使ってるらしい。
- Projection
Conv1d一層のみのネットワークで、潜在表現を入力にとり、平均と分散を出力することで多変量正規分布に置き換えます。
- Flow
逆変換可能で、確率変数の変数変換のために必要なヤコビアンが1になるようにうまーく設定されたネットワークです(あまり分かってない)。その性質により対数尤度が明示的に計算できます(あんまり分かってない)。役割は潜在変数から話者固有の情報を切り離すことです。逆変換可能なので、話者の入れ替えが可能になるということですね。またヤコビアンが1であることから、Projectionの出力分布からの変数変換を容易に行えます(分かってない)。Posterior Encoderと同じくWAVEGLOWの構造が使われているようです。
論文ではText Encoder、Projection、Flowを合わせてPrior Encoderと呼んでいます。
- Discriminator
音声が本物か生成されたものかを判定するネットワークです。DiscriminatorとVAEのDecoderが競いあうことで、精度をあげていきます。学習時は出力だけでなく、中間層の特徴量も真贋で一致するように損失が定義されます。
- Stochastic Duration Predictor
潜在表現から音声の発音時間を推定するためのネットワークです。学習時には潜在表現、話者ID、各音素のdurationを入力し、多変量正規分布にしたがったノイズを出力するよう学習します。推論時には潜在表現と話者ID、ノイズを入力としてdurationを出力します。2つのFlowがありますが、一方は一次元で離散的なdurationデータを高次元連続的なデータに落とし込むためのもので、推論時には使われません。(全然分かってない)
各状態について
各ネットワークの入力や出力の状態が一体どんな意味を持っているのか分かりづらかったのでまとめます。
- スペクトログラム
入力データそのもので、横軸に時刻、縦軸に周波数をとった振幅のデータです。短時間フーリエ変換によって求めるやつ(分かってない)。
- メルスペクトログラム
スペクトログラムにメル尺度をとって、人間にとって直感的な指標に変換します。pHとか星の等級とか、マグニチュードと同じようなやつですかね(分かってない)。再構成誤差を計算するときは、こちらを使うことでより人間にとっていい感じの音声を生成できるようにします。
- 話者情報を含む潜在変数
音声がもつ潜在的な情報で、それが正規分布となるように学習することによって色々と扱いやすくしています。
- 話者情報を含まない潜在変数
潜在変数から話者固有の情報を切り離し、一般的な発音の情報を抽出したものです。Flowにより話者情報の入れ替えが可能です。
- (テキストエンコーダによる)潜在表現
音素列をエンコードしたものです。そのままでは発音の長さの情報を持たないので、それを推定する必要があります。
- (Projectionによる)発音情報の平均と分散
潜在表現から多変量正規分布を出力します。学習時にはMonotonic Alignment Searchにより、この分布から潜在変数が出力される確率(尤度)が最大になるものをdurationとし、推論時はStochastic Duration Predictorからdurationを決定します。
推論フロー
テキストから音声への変換の場合、テキストを音素列に変え、音素列をテキストエンコーダに入力し、潜在表現を得ます。Stochastic Duration Predictorで各音素の発音時間を推定した後、逆Flowで話者情報を付与した潜在変数を獲得し、Decoderで音声を生成します。
音声変換の場合、音声をPosterior Encoderで潜在変数に変え、Flowと逆Flowにより話者情報を変換します。そしてDecoderで音声を生成します、
損失関数
Reconstruncion Loss:入力のメルスペクトログラムと出力のメルスペクトログラムの絶対値誤差です。ラプラス分布ってなんですか。
KL loss:通常のVAEと違って事前分布に条件(音素)が付いているので、項が増えています。その項がFlowやテキストエンコーダの損失関数に該当するという感じですかね。
Adversarial loss:GANの損失です。
Feature matching loss:識別器の中間層も本物の音声と同じような特徴を持つようにします。絶対値誤差の平均をとっているようです。
Duration loss:Stochastic Duration Predictorの損失ですが、よく分かりません。