今回はなぞのおぷてぃまいざーであるAdafactorについて論文の内容を見ていきます。
arxiv.org
概要
AdafactorはAdamを元にした最適化アルゴリズムで、メモリ容量の削減とパラメータスケールに応じた学習率の調整を行う手法です。勾配の二乗指数平均をランク1行列で近似することによって、サイズを減らしています。勾配の指数平均の方はカットして、その代わりに色んな工夫がなされています。

Adamについて
ステップ数をと、
が1よりちょっと小さい値を設定するハイパーパラメーターで、学習率が
、更新対象のニューラルネットワークを
で重みを
とします。するとAdamの更新ステップは以下の通りです。
は分母が
になるのを防ぐための微小量です。2行目が勾配の指数平均であり、ここでは一次モーメントと呼ぶことにします。3行目が勾配の二乗指数平均であり二次モーメントと呼びます。一次モーメントは過去の移動経路を元に慣性をつけるような役割となり、うろうろ動くことを防止します。二次モーメントは過去の移動の大きさを元に移動を制限するような項目であり、変化量が大きすぎるパラメータにじっとしておけ!と命令することでこれもまたうろうろ動くことを防止できます。4行目、5行目に関してはバイアス補正と呼ばれるもので、後で紹介しますが、学習の初期ステップでの精度低下を補正するものになります。
が大きいときは係数が1に近づき効果がないことが分かると思います。
このAdamという最適化関数はもはやディープラーニング業界のデファクトとなっています。ただし明確な欠点として、各パラメータの一次モーメントと二次モーメントを記憶しなければならないということがあります。学習対象のパラメータサイズの二倍のメモリが追加で必要になるので、大きなモデルを学習するのが難しくなります。対策として記憶精度を8bitにするbitsandbytesや、CPUにオフロードするdeepspeed等がありますが、Adafactorは、二次モーメントのサイズを小さくする手法になります。
二次モーメントの低ランク近似
重み行列に対して、二次モーメント
があるとします。低ランク近似
によってメモリ効率を上げることを考えます。一般的に低ランク近似には特異値分解が用いられます。特異値分解はフロベニウスノルムによる距離を基準にした低ランク近似になります。以前の記事を参照してください。しかし各ステップごとに二次モーメントを特異値分解をするのは、計算量が大きくなり非効率的です。さらに二次モーメントは平方根をとることから非負である必要がありますが、特異値分解による低ランク近似は非負性を保証しません。
そこで論文では一般化KLダイバージェンスというものを距離とした近似を行います。この距離は
の中身をみれば分かる通り、
が両方0より大きい(または小さい)とき定義できますが、二次モーメントは二乗指数平均なので全要素が正になります(0になる可能性はある)。
という不等式から、
を代入すると、
で等号成立条件は
になることがわかります。
が成り立つとは限らないので正確には距離ではないですが、まあそれはおいときます。この距離を基準にした低ランク近似の最適解は、一般のランク
に対しては簡単には求められないらしいですが、ランク
のときは簡単に求められます。ランク
というのは
が列ベクトル、
が行ベクトルになるという意味です。このとき
の
要素は
の
番目の要素
と
の
番目の要素
の積になります。つまり
になります。このとき
と
の距離は、
となり、距離が下に凸()であることから、最適解は
で微分して0になる値になります。
このままではを計算するために
が必要で、
を計算するために
が必要で・・・と無限ループに陥ります。そこで最適解について、
であることから、どっちかになんかをかけてどっちかにその逆数をかけたものも同じく最適解になります。この性質をつかえば、
になるよう正規化してあるような最適解を作ることができます。このとき、
となります。は
の行ごとの和であり、
は
の列ごとの和を正規化したものになります。これによって計算可能になります。さらに、指数平均と行や列ごとの和の順序が可換であることから、
の指数平均を計算するだけで済みます。
つまり、
となりますが、
であり、わざわざ次ステップのを計算せず
から直接
が求められます。
に関しても、分子は列ごとの和ですから同様に計算できて、分母は正規化定数に過ぎないので分子を計算してから求めればよいです。
この原理を使ったアルゴリズムは以下の通りになります。
Adamと違って大文字になっているのは行列になっているからです。なんでが
になってるの?とかなんで
側を正規化することにしたの?とか思いますが論文にそう記述されているからしょうがないです。一次モーメントは正負がばらばらで一般化KLダイバージェンスが定義できないので、同様の操作はできませんが、Adamのアルゴリズムをそのまま適用することも可能です。ただし論文では二次モーメントのみで何とかなるような工夫が色々議論されています。
二次モーメントの問題
二次モーメントのハイパーパラメータであるは、指数平均でどれだけ過去の情報を大事にするかという数値です。このパラメータは大きくしても小さくしても問題がでてくるようです。大きくすると、過去の情報を大事にするわけですが、学習初期に
の収束が遅くなり、安定しなくなります。そのため学習初期の学習率を小さくするwarm upが必要となります。逆に小さくすれば、
が早期に収束し、初期段階の不安定性がなくなりますが、
が振動しやすくなって、モデル自体の収束に悪影響を及ぼします。
Update Clipping
前節の問題を解決するため、勾配クリッピングのような手法が提案されています。Update Clippingでは最終的な更新行列であるに対して、以下の指標を使います。
ようするに現在の二乗勾配とその指数平均との比をとって要素ごとに平均しています。平均との比なので、1から大きく離れていると不安定性の原因となり得ます。そこで、閾値に対して、
として
になるようクリッピングします。
 のスケジューリング
のスケジューリング
もう一つの解決法として、学習初期段階ではを小さくして、だんだん大きくしていくという解決策があります。実はAdamの4,5行目の謎のスケーリングはこの戦略を実現しています。
という風にスケジューリングすることを考えます。
のとき、
となり
から
に増加していきます。ここで、
となって、スケーリングとスケジューリングが同値になることが分かります。しかし論文ではこれを使うのではなく、というスケジューリングを行うそうです。この理由も長々と数式が書かれていましたが、面白くなさそうなのでカット。
Relative Step Size
学習率を絶対的に定義するのではなく、パラメータスケールに基づいて相対的に定義します。
ここではスケジューリングのための係数です。また重みが0で初期化されているときでも対応できるように、
で下限をとっておきます。今まで結構理論立てて説明していた割に、この部分はさらっとした説明と実験結果のみで終わっています。
最終的なアルゴリズム
特に説明が見つからなかったですが、は二乗勾配が0にならないようにする微小量です。これは一般化KLダイバージェンスが0で定義できないことからきていると思います。これによって6行目の分母に足す微小量は必要なくなります。論文ではハイパーパラメータを以下のように設定しています。
について、1個目はwarm upなし、2個目はwarm upありになります。実際に見てみましょう。

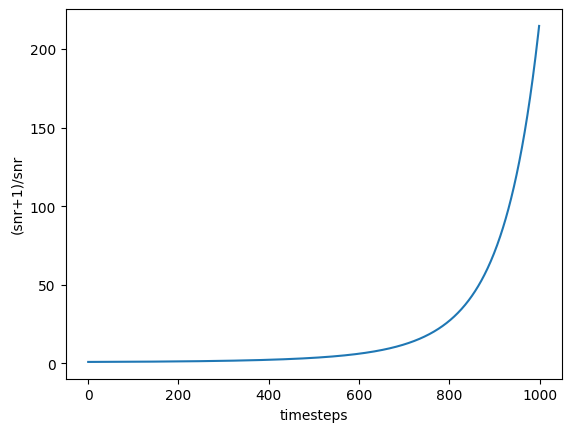
10000ステップまで固定で、その後は無理関数的に減少していきます。warm upの場合は10000ステップまで線形に増加して、warm upなしの場合と合流します。
ちなみにバイアス項等の重みが行列ではなくベクトルの場合は低ランク近似を行わないこと以外は同じです。
実装
transformersによって実装されています。
( lr = None, eps = (1e-30, 0.001), clip_threshold = 1.0, decay_rate = -0.8, beta1 = None, weight_decay = 0.0, scale_parameter = True, relative_step = True, warmup_init = False )
デフォルトの設定は論文通りになっているようですね。一次モーメントも利用するbeta1や、重み減衰を実装するweight_decayなども設定できるようですね。scale_parameterがによるスケーリング、relative_stepは学習率を無視して
を使うという項目になります。
Stable diffusionの学習における考察
Stable-diffusionの、特にLoRA学習でよく使われているみたいです。学習率を自動で決めてくれる代わりに、収束が遅いといった印象のようですね。実際LoRAの学習で使う場合に注意しなければいけない点が結構あると思います。
1. 学習率が自動で決まるという触れ込みだが、学習率に関わるハイパーパラメータは存在する。
学習率はや
といったハイパーパラメータに影響します。といってもなぜか
はハードコーディングされていて設定できないんですけどね(relative_stepで無効にすることはできる)。たとえばLoRAのUP層は初期値が0なので、学習初期はデフォルトの設定だと1e-5に固定されます。これは小さすぎる気がしますね。収束が遅いと呼ばれる原因がこれなら、ここを変えてみるのもありかもしれません。
2. 一次モーメントを使わないので収束が遅い?
Adafactorの収束が遅いのは、一次モーメントを使っていないことも原因かなと思います。メモリに余裕があるならbeta1を設定してみるのもいいかもしれません。
3. rank(dim)の低いLoRAに対してメモリ効率化効果が薄い
Adafactorは二次モーメントの低ランク近似を行いますが、そもそもLoRAは重みそのものに低ランク近似を行っているので、rankの低いLoRAを学習する場合、メモリ容量の削減効果は薄くなります。
4. ステップ数が少ないと学習率スケジューリングの効果がない、warmupの設定は危険
relative_stepをTrueにしたとき、Adafactorの学習率スケジューリングは上のグラフにある通り10000ステップまで定数になります。LoRA学習時はそんなに学習することあまりないと思うので、ほとんどの場合定数スケジューラーになります。さらにwarm upにいたっては、10000ステップまで線形に上昇していくので、むしろ良くないと思います。しかもこの10000ステップという基準は設定で変えられません・・・。
5. DyLoRAとの相性が悪い
DyLoRAは1ステップごとにLoRAの各列各行を選んで更新するので、Adafactorと併用できないようですね。